Alpha Release Prototype:
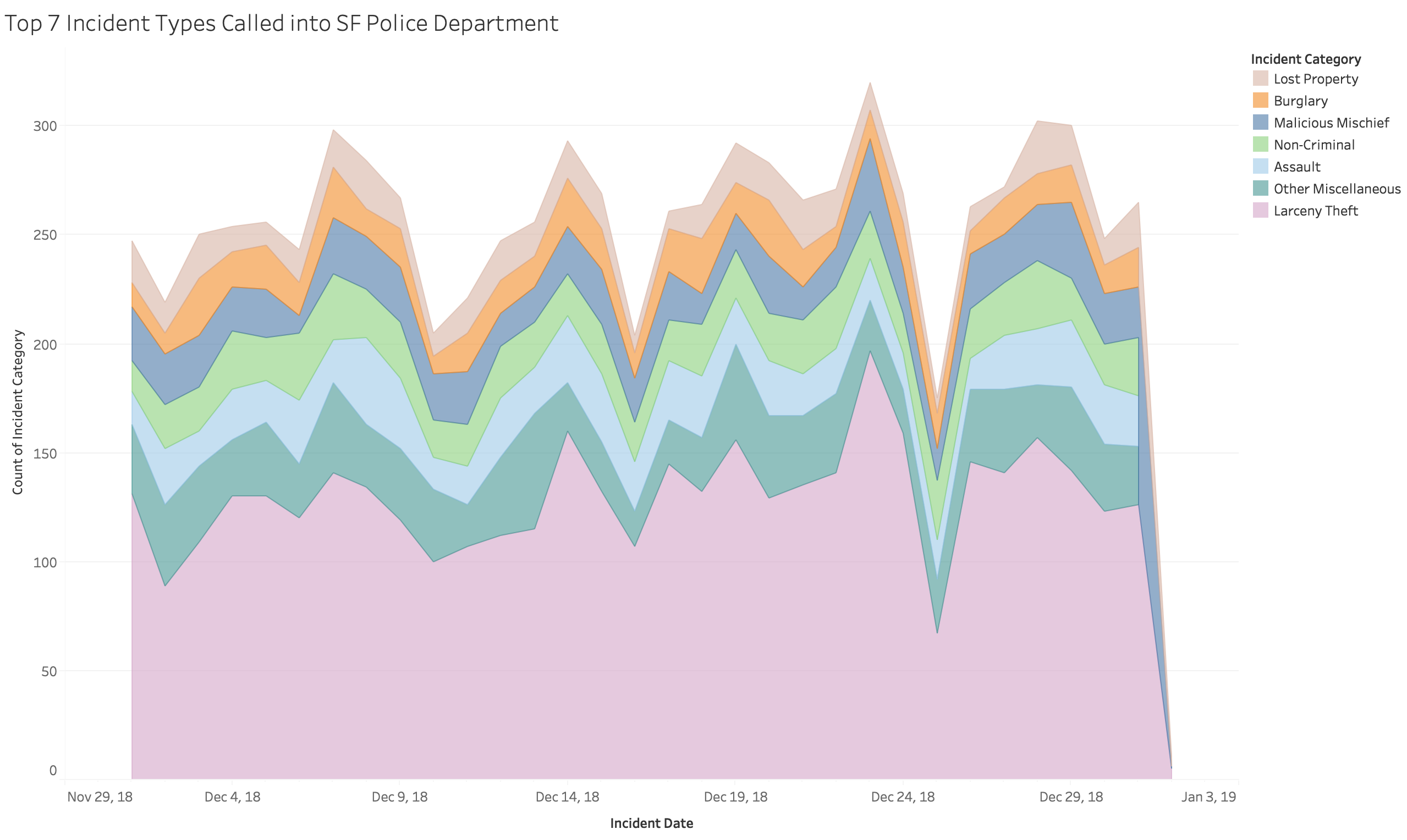
Purpose of Prototype:
My goal for this visualization is to get an idea on what type of crimes make up the majority of the crimes in SF. I limited the number of crime categories to 7 for the purpose of this area chart and I am planning to focus more on the top 3 types of crime incidents since this dataset does provide descriptions to the crime as well. This is a stacked area chart where the data column is encoded as x position on a linear scale and the number of incidents (i.e. the count of all incident categories on a specified day) is encoded on the y axis. The areas are differenciated by the incident categories column and is limited to show only the top 7 incident categories sorted by the count of incident categories.
Feedback after Alpha Release:
I recieved feedback about adding a tooltip that describes the date, incident category, and the number of incidents for that category while hovering over the data. I also recieved the suggestion of having linked views, as well as a bar chart for a legend rather than just an ordinary legend.
Changes made:
One of the main differences between these two charts is the way the date from the data is used. The prototype handled a bigger selection of dates, ranging from the beginning of 2018, 1/1/18 to the present. Tableau had issues differenciating the overlapping months and days, so this protype did not come out as clearly as hoped. In regards to this issue I decided to only use all the data from 2018 and use months as my tick marks for my x-axis instead of long dates. This provided a cleaner look for the visualization. Another change I made was adding another chart that shows the different areas to each of the categories in the stacked area chart as it is hard to imagine these areas separetly.
Beta Release Prototype:
Purpose of Prototype:
This Treemap visualization's purpose is to see what is the main type of incident that is recorded in each neighborhood. This can help citizens be more aware of what is the most common crime for each area in San Francisco, and be cautious as needed. This is a Treemap visualizing the hierarchy of the categories Analysis Neighborhood and Incident Category from the dataset. The color of the dataset is based off of the category, Analyis Neighborhood and each group is labeled based on the Incident Category. The hiearchial levels of Analysis Neighborhood and Incident Category create visual clusters of SF Neighborhoods through subdivisions based on the type of incident recorded. This treemap was created with the help of RAWGraphs.
Feedback after Beta Release:
Visual encodings: The overall visual encoding is nice, it'd be better to put the labels only if it can fit into the cells. The data has both color encoding and size encoding. They both seem to be working well
These are used very well. The coloring, labeling, and varying sizes of the treemap is effective at conveying your desired goal. Color = neighborhood and category?, Size = count, and text = crime category.
The overall visual encoding is informative. Every requirement in project is satisfied.
Non-color encodings: I think the choice of the visual encoding is very effective for comparing the incident/neighborhood number. The size is used for the tree map. I think this will help understand the total crime in each neighborhood.
I believe the only non-color encodings would be the labels included, but this isn't a problem. There is no size legend, so it's difficult to tell the count. The data size is appropriate I love it.
Color encodings: The overall color encoding is good. Might need to consider for color blind and maybe choose distinguishable color beside each other. If you add the planned legend showing the different neighborhoods, it should be good
Coloring the different neighborhoods is a very effective idea, but choosing colors that allow the viewers to differentiate between one another would be helpful. Some of the neighborhoods have similar colors.
The colors of the neighborhoods are really similar. Maybe use more discrete colors? Also a legend would really help here. It's hard to tell what the colors mean at first glance. I love your first visualization. And in your second visualization, there are some very similar colors representing different districts. If the color can be more unique, that would be perfect!
Context: The context would be well given if including the legend but I can get a lot of information from data page and the write-ups under the prototype. Adding proposed legend will be good.
Each visualization is very well documented and explained. Had no difficulty understanding what each visualization was trying to accomplish. All the information is enough provided.
Lie Factor: The visualization is very straightforward, no lie factor I can tell. Since the proposed interactivity will show the count of the incidents, it is easily understandable. No lie factor detected.
There is a possibility for the lie factor to be pretty large with these visualizations but with the planned interactivity of including tooltips and detailed statistics, I think you can combat the potential of this lie factor really well. One little thing, in the first visualization, all lines are increasing and decreasing at exact the same time. I am wondering if it is what really happens...
Data Ink Ratio: The majority parts of the graph is taken by the data itself.More ink is used for data. Labelling can be on hover as proposed.
Basically all the ink that is used is for the sole purpose of representing some kind of data, so nice job with this! The ratio is appropriate.
Data Density: Very good padding between cells to distinguish different categories. A lot of data is encoded in the visualization.
Again, including the tooltip will allow for this to become a much more dense visualization. Data Density is appropriate.
Gestalt Principles: I don't see any misleading between foreground and background. Good and appealing colors were used.
The differing neighborhoods have some similarities in their color, which makes it difficult to interpret data appropriately at times, but overall with small tweaks in color this can be fixed easily. You applied Gestalt principles pretty well.
Planned Interactivity: Planned interactivity would give user more information to understand the story underneath. Planned interactivity is fitting the scenario. Mouse hover will help understand more about the neighborhoods.
You proposed a lot of good ideas for your interactivity. This will make your graphs really stand out. The planned interactivity will bring the entire visualization together. I hope you accomplish the goals you have for it because i think it would make for really great visualizations!
The planned interactivities makes the visualization more informative. I like that.
Planned Interation Effectiveness: By adding the planned interaction should improve the context and Effectiveness a lot. Mouse hover which is details on demand is working well for the tree map.
Adding a tooltip that drills down into the specifics of crime rates in the varying neighborhoods of San Francisco would not only deepen our understanding, but it would also further accomplish your goal of educating/inciting us to do more individual research should we live in one of those neighborhoods.
Design and Aesthetics: The design and Aesthetics are clean and neat. Colors are very good and not distracting.
The tree map is a little cramped so maybe spacing a bit more would be helpful. Other than that, it's aesthetically pleasing to look at. Maybe you can have some clear indicator (a surrounding box maybe) for neighborhoods. A legend would be very helpful. Overall website design is pretty good, clean, and organized.
Understanding: I can compare between neighborhoods regarding the crime incident frequency. Learned that Larceny category has more count in all neighborhoods.
Super easy to understand your points. A very interesting point you raised was crime rising and lowering together. I hope to see you investigate that more and provide some insight in terms of why that happens. Fraud and larceny/theft seem most frequent. I can tell the most frequent happened crime type in a specific district.
Visualization Goal: The goal here is very clear, it helps to conclude the overall crime activity in San Francisco. Since the theme is to do crime data analysis of SF, it fits the theme. The goal was to visualize the distribution of crime types and count by neighborhood.
Some suggestions I would have is to maybe change the colors of the stacked area chart, fix the wording of the tree map to be easier to see, and to really nail the interactivity. Promoting others to learn more about their neighborhoods. I can definitely do more to learn about the area I live in, so I think this is a good way of inciting others to do the same. To understand the crime happened in SF with more details.
Visualization Effectiveness: The chosen visualization is the more effective one for presenting this type of information. Very good. The tree map is easy to understand. Simple yet effective way of showcasing something as important as crime in neighborhoods. I look forward to seeing you tie it all together! It's a little hard to understand the visualization without a legend. Very nice!
Changes made:
The main change I made to my new visualization was again, the date range. Before, I was using data from beginning 2018 to the present, which have might have been affecting the size of each area in this treemap. Using only 2018 data already shows a difference in the layout of the chart. Another change I did was use Tableau rather that RAWGraphs This provided a better looking aesthetic to the chart and helped with showing the top neighborhoods as well as the Incident Categories.